Accédez à 100 % de vos connaissances d'entreprise et surveillez vos marchés en 1 clic
4 workflows IA qui centralisent toute votre mémoire documentaire, surveillent les opportunités de marché, et classent automatiquement vos documents — pendant que vous vous concentrez sur vos dossiers.
4
Workflows actifs
75
Nodes total
Drive + Pappers + marchés publics
Sources surveillées
Le constat : votre savoir est dispersé, vos opportunités passent sous le radar
Votre entreprise accumule des années d'expertise dans des documents, des emails et des notes. Mais personne ne sait exactement où chercher — et pendant ce temps, vos concurrents captent les marchés en premier.
Des heures perdues à chercher un document
Le contrat signé en 2023 ? Le compte-rendu de réunion avec ce sous-traitant ? La note technique du bureau d'études ? L'information existe quelque part — dans un Drive, un email, un dossier papier, ou dans la tête d'un collaborateur parti depuis six mois. Chaque recherche prend entre 15 et 45 minutes. Multipliez par cinq collaborateurs, cinq fois par jour.
Des opportunités de marché découvertes trop tard
Un appel d'offres public dans votre secteur a été publié il y a trois jours. Un concurrent direct est en procédure de redressement judiciaire. Vous l'apprenez par hasard, au détour d'une conversation. Trop tard pour réagir. L'entreprise qui surveille ces signaux en temps réel décroche le marché — pas vous.
Des silos d'information entre services
Le service juridique utilise un Drive. La direction technique stocke dans un NAS. La comptabilité travaille sur un autre outil. Personne n'a une vision consolidée. Les décisions stratégiques se prennent avec des informations partielles — et parfois obsolètes.
Un classement documentaire qui repose sur la bonne volonté
Les documents entrants — factures, contrats, courriers, PV de réception — s'empilent dans une boîte de réception commune. Le classement dépend de qui les traite, quand, et selon quelle logique. Résultat : des doublons, des fichiers mal nommés, et des pièces introuvables lors d'un contrôle ou d'un litige.
L'assistant RAG documentaire
Posez une question en français, obtenez la réponse depuis vos propres documents
L'assistant indexe l'ensemble de vos documents professionnels — contrats, notes, rapports, emails archivés — dans une base vectorielle. Vous interrogez cette base en langage naturel, comme vous poseriez une question à un collaborateur expérimenté. La réponse cite ses sources avec les passages exacts.
- Indexation automatique de vos documents Google Drive (PDF, Word, tableurs, présentations)
- Recherche sémantique : trouvez un document par son contenu, pas seulement par son titre
- Réponses en langage naturel avec citation des sources et passages pertinents
- Mémoire cumulative : plus vous alimentez le système, plus il devient précis
- Accès instantané à des années d'expertise — même si le collaborateur qui détenait l'information est parti
La veille procédures collectives
Sachez avant tout le monde quand un concurrent ou un client est en difficulté
Le workflow surveille en continu les annonces de procédures collectives (redressement, liquidation judiciaire) dans votre secteur et votre zone géographique. Chaque alerte est vérifiée via l'API Pappers pour confirmer l'identité de l'entreprise et enrichir le contexte. Vous recevez une notification exploitable — pas du bruit.
- Surveillance quotidienne des annonces légales de procédures collectives
- Filtrage par secteur d'activité, zone géographique et taille d'entreprise
- Vérification croisée automatique via l'API Pappers (SIREN, statut, dirigeants)
- Notification immédiate avec fiche synthétique : qui, quoi, depuis quand, quel impact potentiel
- Détection précoce de risques fournisseurs et d'opportunités de reprise
La veille marchés publics
Les appels d'offres pertinents, filtrés et livrés chaque matin
Le workflow scrute les plateformes de marchés publics, filtre les appels d'offres par secteur, montant et zone géographique, et vous livre chaque matin une sélection qualifiée. Plus besoin de passer une heure par jour sur BOAMP ou les plateformes régionales — le système fait le tri pour vous.
- Collecte automatique des marchés publics (BOAMP, plateformes régionales, JOUE)
- Filtrage intelligent par code CPV, secteur d'activité, montant estimé et localisation
- Analyse IA du cahier des charges pour évaluer la pertinence par rapport à vos compétences
- Synthèse quotidienne avec les marchés les plus pertinents et leurs dates limites
- Alerte prioritaire sur les marchés à forte adéquation avec votre profil
L'agent Zero Papier
Chaque document entrant est classé, nommé et rangé automatiquement
L'agent surveille un dossier d'entrée (Drive, email, ou scanner réseau). Chaque document entrant est analysé par IA : type identifié (facture, contrat, PV, courrier), contenu extrait, nom normalisé, et fichier déplacé dans le bon répertoire. Le classement devient systématique — sans intervention humaine.
- Détection automatique du type de document (facture, contrat, devis, PV, courrier)
- Extraction des métadonnées clés (date, montant, parties, référence)
- Renommage normalisé selon votre convention de nommage
- Classement dans l'arborescence cible — chaque fichier au bon endroit
- Indexation automatique dans la base RAG pour recherche ultérieure
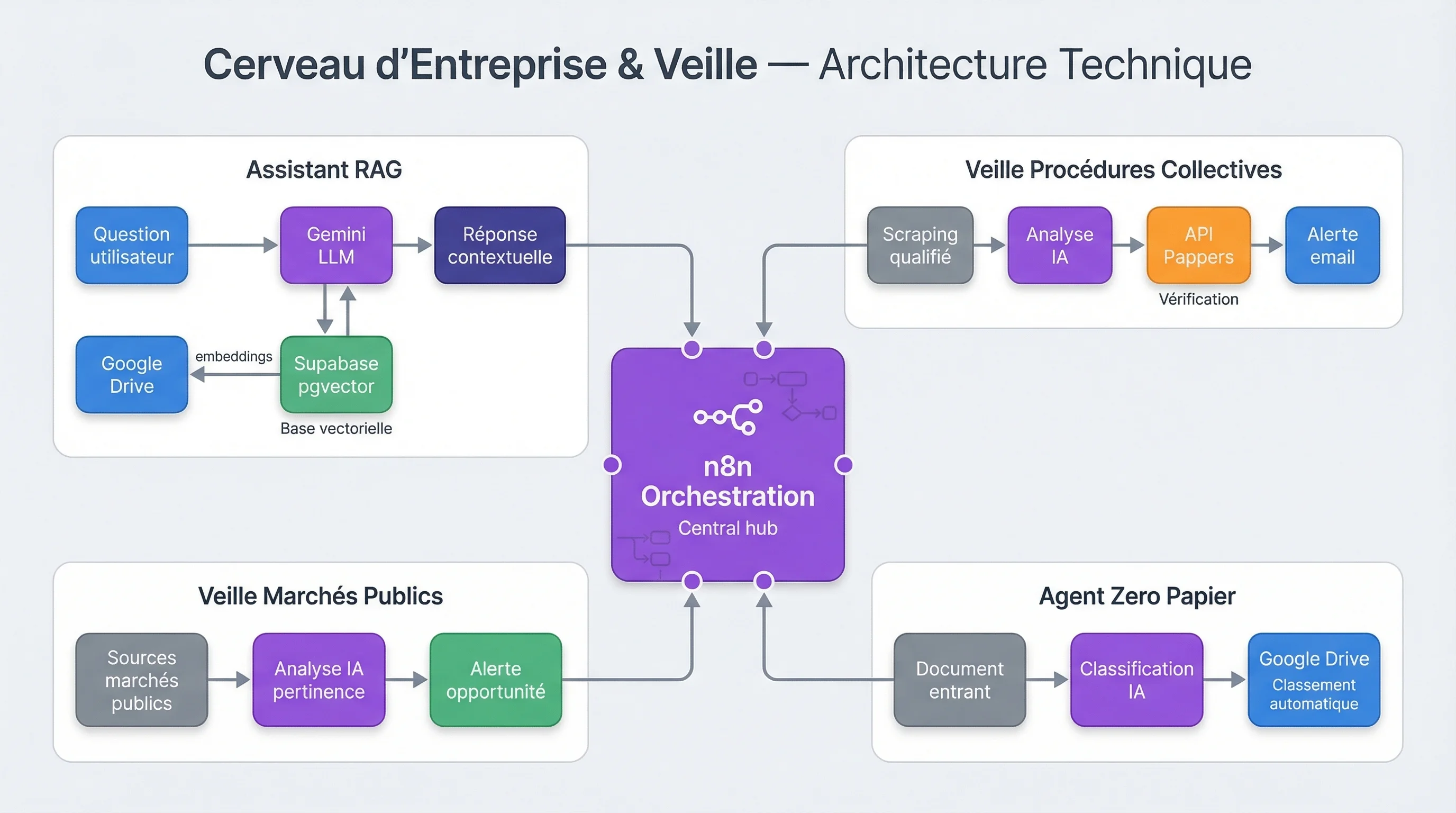
Sous le capot : l'architecture technique
4 workflows interconnectés, 75 nodes au total, orchestrés par n8n. La base vectorielle Supabase sert de mémoire partagée entre l'assistant RAG et l'agent de classement. Les veilles fonctionnent en parallèle, de manière autonome.
n8n (auto-hébergé)
Orchestration — 4 workflows, schedules, gestion d'alertes
Supabase (pgvector)
Base vectorielle RAG — mémoire documentaire et recherche sémantique
Gemini
Compréhension documentaire, classification, génération de réponses
Google Drive
Source et destination documentaire — synchronisation bidirectionnelle
API Pappers
Vérification et enrichissement données entreprises françaises
Scraping qualifié
Collecte ciblée BODACC, BOAMP, plateformes marchés publics
Pourquoi ces choix techniques ?
Technologies utilisées
Questions fréquentes
Vous voulez un cerveau d'entreprise qui travaille pour vous ?
Réservez un audit gratuit de 30 minutes. On identifie ensemble vos sources documentaires, vos besoins de veille, et le potentiel d'un assistant RAG pour votre activité.
Réservez votre audit IA gratuit (30 min)